Image Captioning using Unidirectional and Bidirectional LSTM
Generate a caption which describes the contents/scene of an image and establishes a Spatial Relationship (position, activity etc.) among the entities.
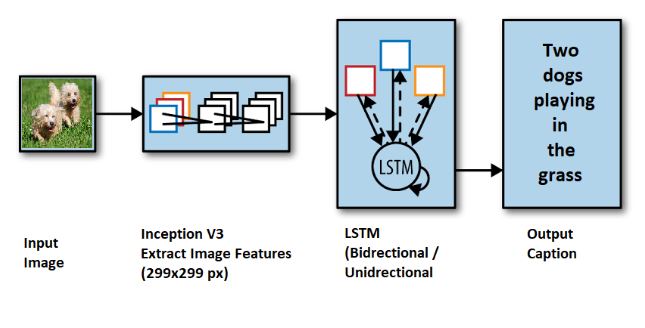
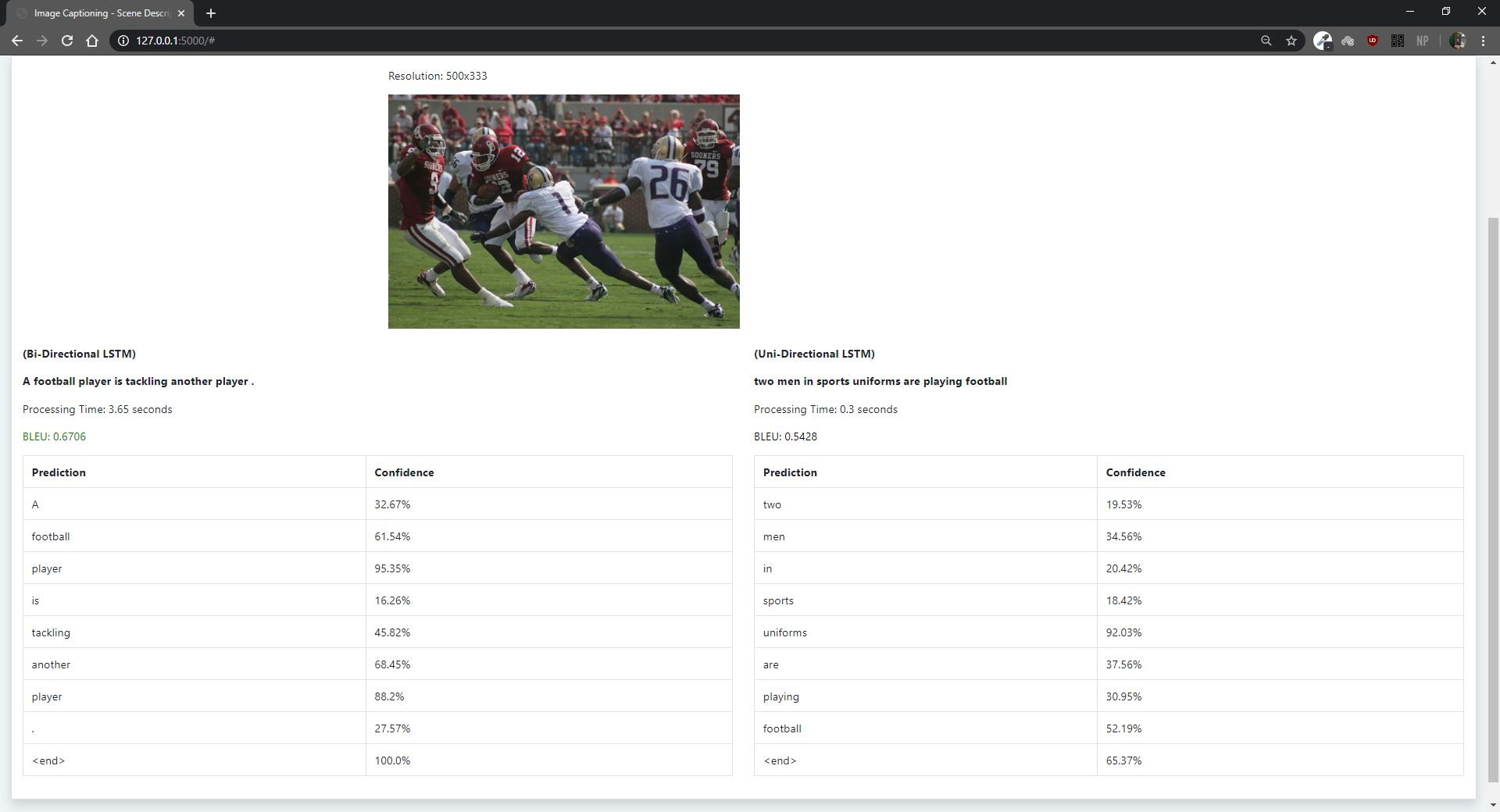
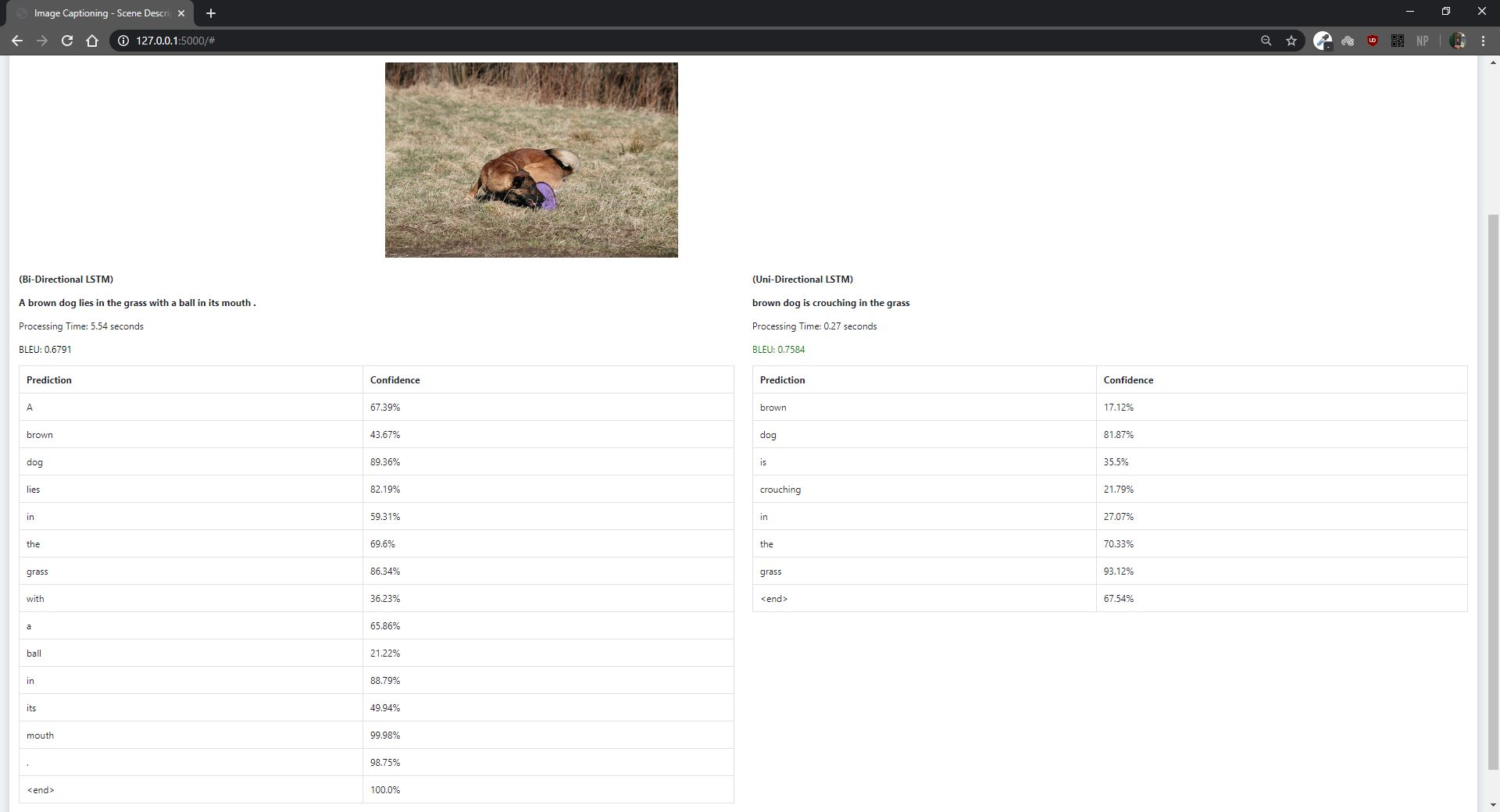


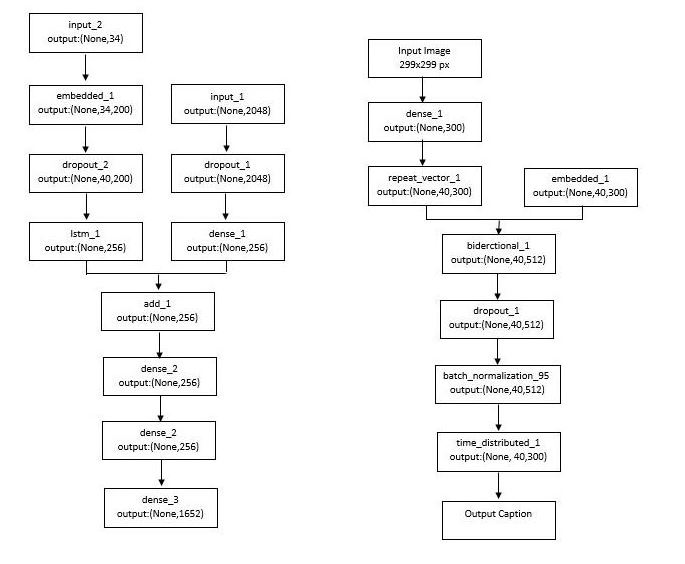
Image Captioning using Deep Learning
CNN-RNN Architecture
- Instead of simply detecting the objects present in the image, a Spatial Relationship among the entities is established.
- Uses a Convolutional Neural Network (CNN) to detect entities and a Long-Short Term Memory Network (LSTM) to generate a caption.
- Image Features are extracted using InceptionV3 model (Transfer Learning).
- 2 approaches have been implemented: Unidirectional and Bidirectional LSTM along with Greedy and Beam Search to predict the caption.
- Trained on the Flickr8k Dataset using Google Colab.
- The BLEU Metric has been used to evaluate the test images. A higher BLEU rating (closer to 1) corresponds to an accurate description.
Tech Stack
- TensorFlow
- Keras
- OpenCV
- RESTful
- Flutter